(一)yolov5检测头head魔改之添加小目标层|针对小目标检测
1.YOLOv5算法简介
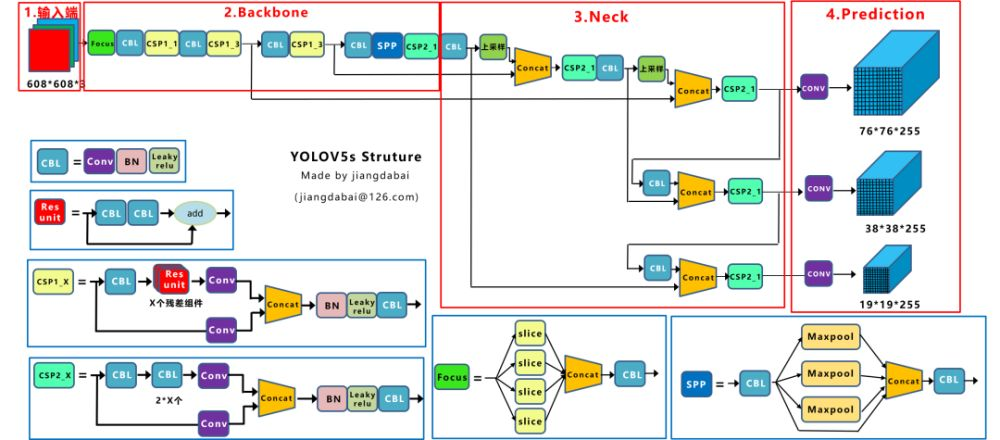
YOLOv5主要由输入端、Backone、Neck以及Prediction四部分组成。其中:
(1) Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
(2) Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
(3) Head: 对图像特征进行预测,生成边界框和并预测类别。
检测框架:
2.原始YOLOv5模型
1 | |
若输入图像尺寸=640X640,
P3/8 对应的检测特征图大小为80X80,用于检测大小在8X8以上的目标。
P4/16对应的检测特征图大小为40X40,用于检测大小在16X16以上的目标。
P5/32对应的检测特征图大小为20X20,用于检测大小在32X32以上的目标。
3.增加小目标检测层
1 | |
上面的代码中根据不同yolov5版本进行适当修改,例如有的版本backbone第一行为[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2,利用卷积取消了Focus,有些版本是C3替换了C2f,backbone第一行为[-1, 1, Conv, [64, 3, 2]] # 0-P1/2,其它yolo系列如yolov7与yolov8原理一样,之不过yolov5与yolov7许哟啊用到anchors,因此anchor也需要在原来基础上增加一个如上,yolov8则不需要,然后都是根据对应版本的原始yaml文件进行更改,只更改head部分即可。
# 新增加160X160的检测特征图,用于检测4X4以上的目标。
改进后,虽然计算量和检测速度有所增加,但对小目标的检测精度有明显改善。
这里给出其它yolov7与yolov8魔改的链接
YOLOv8/YOLOv7/YOLOv5系列算法改进【NO.6】增加小目标检测层,提高对小目标的检测效果_yolov5添加小目标检测层_人工智能算法研究院的博客-CSDN博客
anchor重新聚类方法
https://blog.csdn.net/qq_37541097/article/details/119647026
yolov5中聚类anchors代码讲解
如果你是直接使用yolov5的训练脚本,那么它会自动去计算下默认的anchors与你数据集中所有目标的best possible recall,如果小于0.98就会根据你自己数据集的目标去重新聚类生成anchors,反之使用默认的anchors。
下面代码是我根据yolov5中聚类anchors的代码简单修改得到的。基本流程不变,主要改动了三点:1.对代码做了些简化。2.把使用pytorch的地方都改成了numpy(感觉这样会更通用点,但numpy效率确实没有pytorch高)。3.作者默认使用的k-means方法是scipy包提供的,使用的是欧式距离。我自己改成了基于1-IOU(bboxes, anchors)距离的方法。当然我只是注释掉了作者原来的方法,如果想用自己把注释取消掉就行了。但在我使用测试过程中,还是基于1-IOU(bboxes, anchors)距离的方法会略好点。
其实在yolov5生成anchors中不仅仅使用了k-means聚类,还使用了Genetic Algorithm遗传算法,在k-means聚类的结果上进行mutation变异。接下来简单介绍下代码流程:
读取训练集中每张图片的wh以及所有bboxes的wh(这里是我自己写的脚本读取的PASCAL VOC数据)
将每张图片中wh的最大值等比例缩放到指定大小img_size,由于读取的bboxes是相对坐标所以不需要改动
将bboxes从相对坐标改成绝对坐标(乘以缩放后的wh)
筛选bboxes,保留wh都大于等于两个像素的bboxes
使用k-means聚类得到n个anchors
使用遗传算法随机对anchors的wh进行变异,如果变异后效果变得更好(使用anchor_fitness方法计算得到的fitness(适应度)进行评估)就将变异后的结果赋值给anchors,如果变异后效果变差就跳过,默认变异1000次。
将最终变异得到的anchors按照面积进行排序并返回
1 | |
聚类anchors需要注意的坑
有时使用自己聚类得到的anchors的效果反而变差了,此时你可以从以下几方面进行检查:
注意输入网络时训练的图片尺寸。这是个很重要的点,因为一般训练/验证时输入网络的图片尺寸是固定的,比如说640x640,那么图片在输入网络前一般会将最大边长缩放到640,同时图片中的bboxes也会进行缩放。所以在聚类anchors时需要使用相同的方式提前去缩放bboxes,否则聚类出来的anchors并不匹配。比如你的图片都是1280x1280大小的,假设bboxes都是100x100大小的,如果不去缩放bboxes,那么聚类得到的anchors差不多是在100x100附近。而实际训练网络时bboxes都已经缩放到50x50大小了,此时理想的anchors应该是50x50左右而不是100x100了。
如果使用预训练权重,不要冻结太多的权重。现在训练自己数据集时一般都是使用别人在coco等大型数据上预训练好的权重。而这些权重是基于coco等数据集上聚类得到的结果,并不是针对自己数据集聚类得到的。所以网络为了要适应新的anchors需要调整很多权重,如果你冻结了很多层(假设只去微调最后的预测器,其他权重全部冻结),那么得到的结果很大几率还没有之前的anchors好。当可训练的权重越来越多,一般使用自己数据集聚类得到的anchors会更好一点(前提是自己聚类的anchors是合理的)。