(二)yolov5检测头head魔改之BiFPN|优化小目标检测涨点
1.YOLOv5算法原始head结构
YOLOv5模型的Neck部分使用的是FPN+PAN结构,FPN是针对多尺度问题提出的,FPN结构是自上而下并且横向连接的,它利用金字塔的形式对尺度不同的特征图进行连接,将高层特征和低层特征进行融合。FPN与PAN结合,对来自不同骨干层的不同检测层进行参数聚合。这种组合虽然有效提高了网络的特征融合能力,但也会导致一个问题,即PAN结构的输入全部是FPN结构处理的特征信息,而骨干特征提取网络部分的原始特征信息存在一部分丢失。缺乏参与学习的原始信息很容易导致训练学习的偏差,影响检测的准确性。
从neck特征融合入手,引入加权双向特征金字塔BiFPN来加强特征图的底层信息,使不同尺度的特征图进行信息融合,从而加强特征信息。
2.BiFPN原理与结构
BiFPN是一种改进版的FPN网络结构,主要用于目标检测任务。该结构是加权且双向连接的,即自顶向下和自底向上结构,通过构造双向通道实现跨尺度连接,将特征提取网络中的特征直接与自下而上路径中的相对大小特征融合,保留了更浅的语义信息,而不会丢失太多的深层语义信息。
传统的特征融合时将尺度不同的特征图以相同权重进行加权,但是当输入的特征图分辨率不同时,以相同的权重进行加权对输出的特征图不平等。所以BiFPN根据不同输入特征的重要性设置不同的权重,同时反复采用这种结构来加强特征融合。
BiFPN结构中的加权融合方式采用快速归一化融合(Fast normalized fusion),该融合方式是针对训练速度慢提出的,将权重放缩至0~1范围内,因没有使用Softmax方式,所以训练速度很快。跨尺度连接通过添加一个跳跃连接和双向路径来实现,自此实现了加权融合和双向跨尺度连接。
传统的特征融合往往只是简单的 feature map 叠加/相加 (sum them up),比如使用concat或者shortcut连接,而不对同时加进来的 feature map 进行区分。然而,不同的输入 feature map 具有不同的分辨率,它们对融合输入 feature map 的贡献也是不同的,因此简单的对他们进行相加或叠加处理并不是最佳的操作。所以这里我们提出了一种简单而高效的加权特融合的机制。
常见的带权特征融合有三种方法:
BiFPN结构如图所示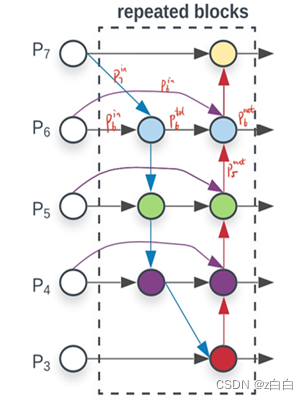
详细结构图如下: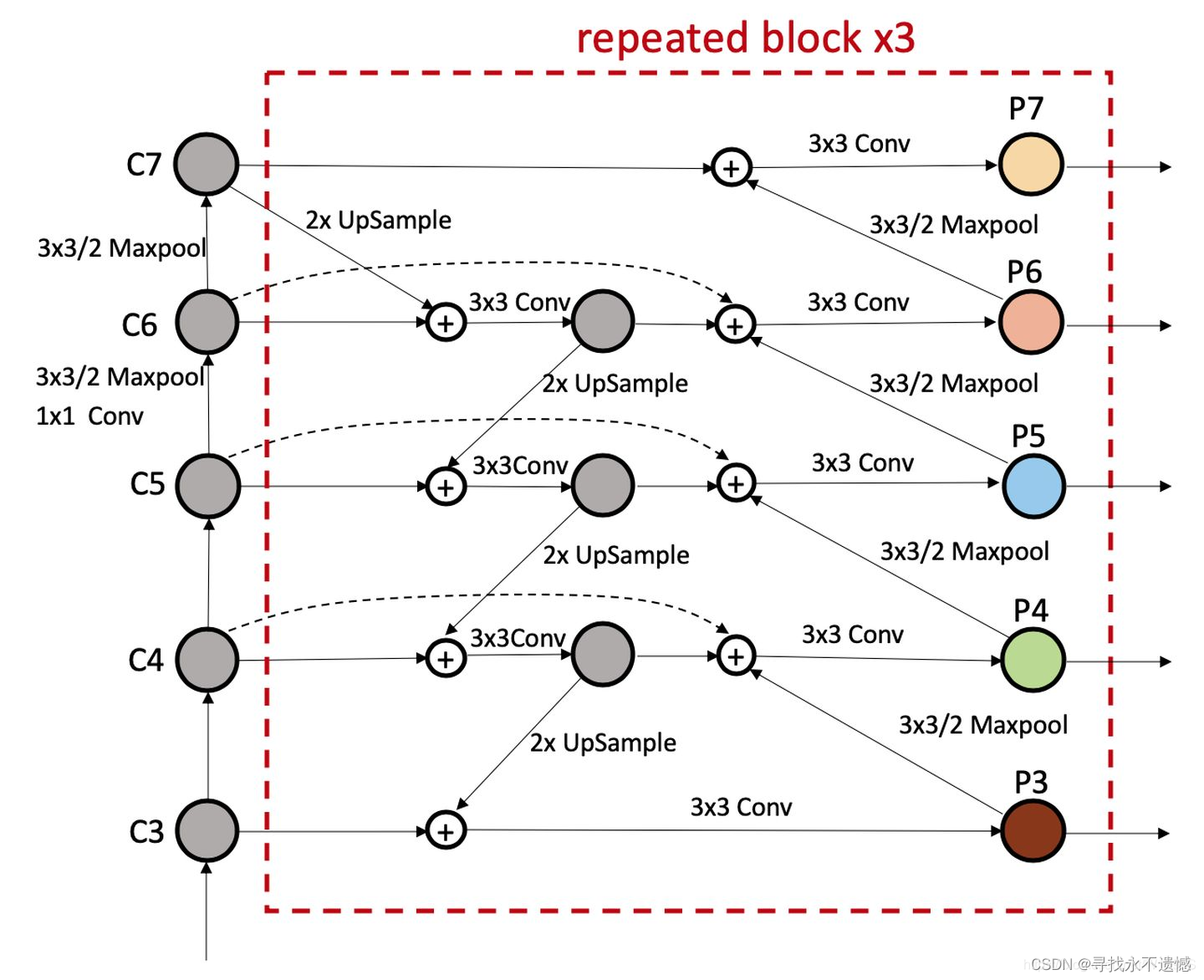
从这张图可以看出图中有三个分支与两个分支融合,对应下面的代码部分
与只有一个自顶向下和一个自底向上路径的PANet不同,我们处理每个双向路径(自顶向下和自底而上)路径作为一个特征网络层,并重复同一层多次,以实现更高层次的特征融合。如下图EfficientNet 的网络结构所示,我们对BiFPN是重复使用多次的。而这个使用次数也不是我们认为设定的,而是作为参数一起加入网络的设计当中,使用NAS技术算出来的。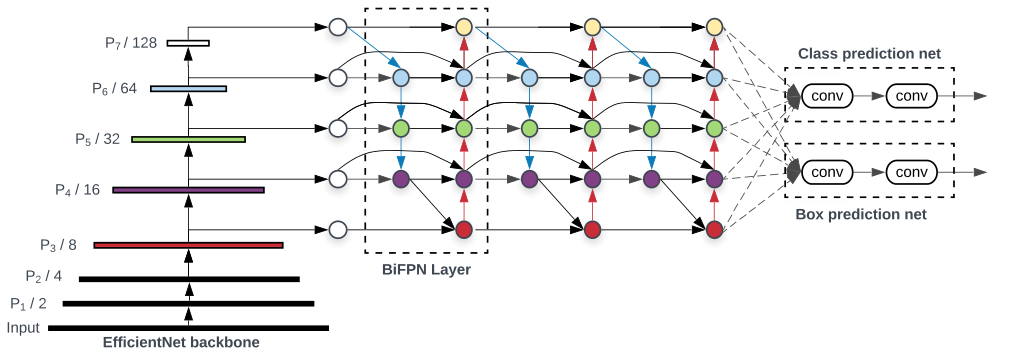
根据上面可以看出,BiFPN其实就是融合了FPN与PAN并增加了跳跃连接来获取浅层信息,所以对于小目标检测效果比较好。
3.代码与文件修改
在Common.py中添加定义模块(Concat)
1 | |
修改yolov5s.yaml
BiFPN_Concat本质是add操作,不是concat操作,因此,BiFPN_Concat的各个输入层要求大小完全一致(通道数、feature map大小等),因此,这里要修改之前的参数[-1, 13, 6],来满足这个要求:
-1层就是上一层的输出,原来上一层的输出channel数为256,这里改成512
13层就是这里[-1, 3, C3, [512, False]], # 13
这样修改后,BiFPN_Concat各个输入大小都是[bs,256,40,40]
最后BiFPN_Add后面的参数层设置为[256, 256]也就是输入输出channel数都是256
1 | |
3.将类名加入进去,修改yolo.py
models/yolo.py中的parse_model函数中搜索elif m is Concat:语句,在其后面加上BiFPN_Concat相关语句
1 | |
4. 修改train.py
1 | |
最后为了方便测试模型配置文件是否正确、模型是否能够正确进行前向传播,以及查看模型的detect层输出,自己就编写了这个函数
1 | |
pytorch获取模型某一层参数名及参数值方式
1 | |