(三)yolov5检测头head魔改之CBAM,ODConv|添加注意力
1.CBAM介绍
论文题目:《CBAM: Convolutional Block Attention Module》
论文地址: https://arxiv.org/pdf/1807.06521.pdf
实验证明,将CBAM注意力模块嵌入到YOLOv5网络中,有利于解决原始网络无注意力偏好的问题。主要在分类问题中比较明显
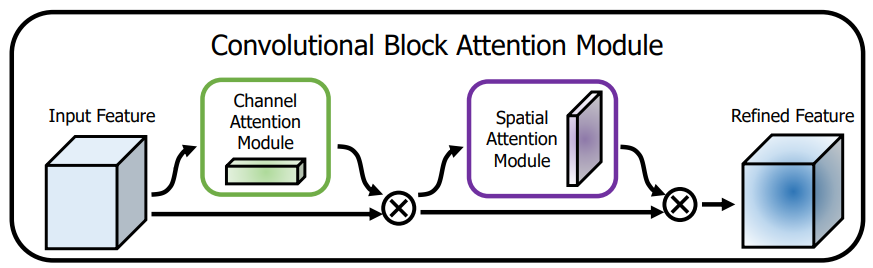
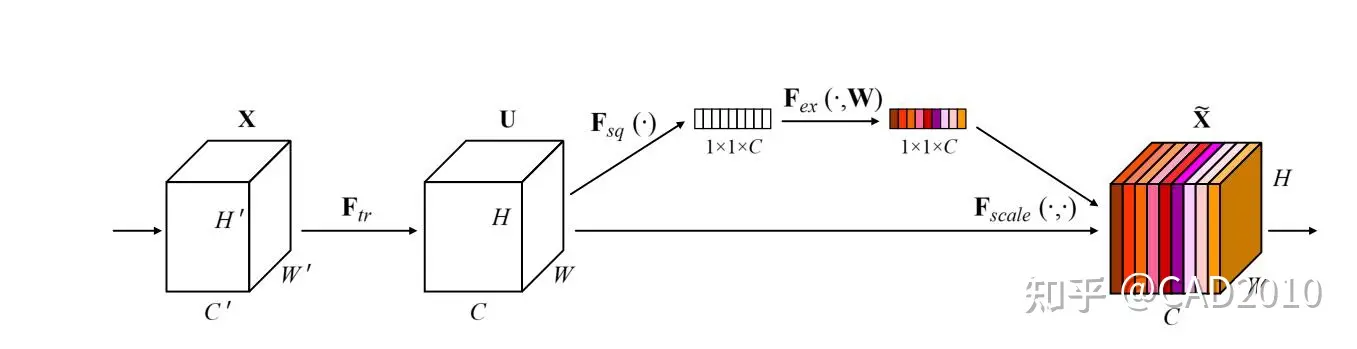
CBAM注意力结构基本原理:从上图明显可以看到, CBAM一共包含2个独立的子模块, 通道注意力模块(Channel Attention Module,CAM) 和空间注意力模块(Spartial Attention Module,SAM) ,分别进行通道与空间维度上的注意力特征融合。 这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
那对应YOLOv5结合CBAM需要修改哪些地方:
2.common.py中加入CBAM代码
1 | |
3.在yolo.py文件中添加对应的CBAM
1 | |
4.在yolov5s.yaml文件中添加CBAM
根据实际训练效果,在配置文件中的C3模块后面适当添加CBAM注意力模块,过程中注意通道数和网络层数的变化(注:不同添加位置效果可能不大一样),例如下面作为参考:在最后检测层上面添加CBAM,其中BiFPND,BiFPNT分别是二分支与三分支的BiFPN
1 | |
其它注意力SE,ECA与CSBAM区别
注意力机制顾名思义就是通过对感兴趣的区域提升更多的注意力,尽可能的抑制不感兴趣的区域在图像分割中的作用。深度学习CNN中可以将注意力机制分为通道注意力和空间注意力两种,通道注意力是确定不同通道之间的权重关系,提升重点通道的权重,抑制作用不大的通道,空间注意力是确定空间邻域不同像素之间的权重关系,提升重点区域像素的权重,让算法更多的关注我们需要的研究区域,减小非必要区域的权重。
一、SE (Squeeze and Excitation)注意力机制
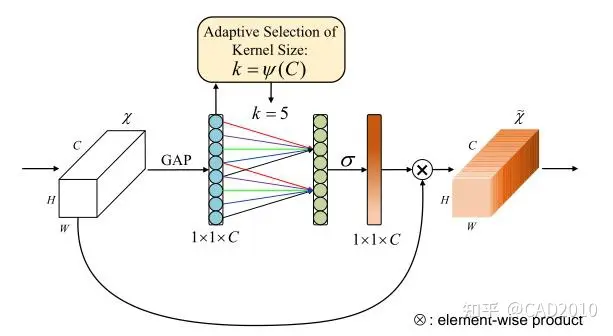
SE注意力机制是通道注意力模式下的一种确定权重的方法,它通过在不同通道间分配权重达到主次优先的目的。如下图所示,为SE注意力机制的结构图。
该结构主要分为以下三个方面:
①:通过将特征图进行Squeeze(压缩),该步骤是通过全局平均池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合。
②:Excitation操作,该步骤使用两个全连接层,通过全连接层之间的非线性添加模型的复杂度,达到确定不同通道之间的权重作用,其中第一个全连接层使用ReLU激活函数,第二个全连接层采用Sigmoid激活函数,为了将权重中映射到(0,1)之间。值得注意的是,为了减少计算量进行降维处理,将第一个全连接的输出采用输入的1/4或者1/16。
③:将reshape过后的权重值与原有的特征图做乘法运算(该步骤采用了Python的广播机制),得到不同权重下的特征图。
具体PyTorch实现代码如下:
1 | |
二、ECA(Efficient Channel Attention)
ECA注意力机制也是通道注意力的一种方法,该算法是在SE算法的基础上做出了一定的改进,首先ECA作者认为SE虽然全连接的降维可以降低模型的复杂度,但是破坏了通道与其权重之间的直接对应关系,先降维后升维,这样权重和通道的对应关系是间接的,基于上述,作者提出一维卷积的方法,避免了降维对数据的影响。
该结构主要分为以下三个方面:
①:通过将特征图进行Squeeze(压缩),该步骤是通过全局平均池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合,该步骤和SE一样。
②:计算自适应卷积核的大小,
,其中C为输入的通道数,b=1,
=2,并采用一维卷积计算通道的权重,最后采用Sigmoid激活函数将权重映射在(0-1)之间。
③:将reshape过后的权重值与原有的特征图做乘法运算(该步骤采用了Python的广播机制),得到不同权重下的特征图。
具体PyTorch实现代码如下:
1 | |
三、CBAM(Convolutional Block Attention Module)
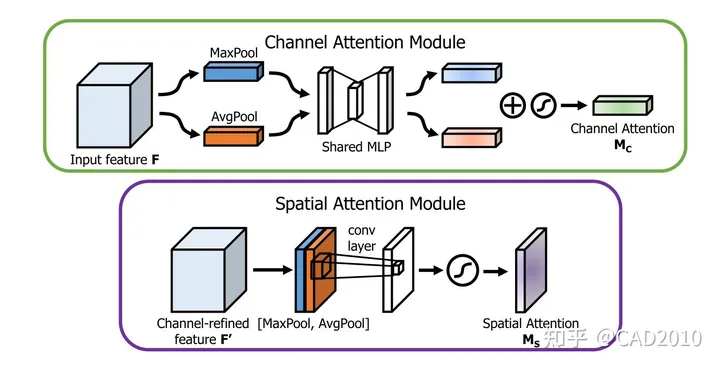
CBAM注意力机制是一种将通道与空间注意力机制相结合的算法模型,算法整体结构如图3所示,输入特征图先进行通道注意力机制再进行空间注意力机制操作,最后输出,这样从通道和空间两个方面达到了强化感兴趣区域的目的。
通道结构主要分为以下三个方面:
①:通过将特征图进行Squeeze(压缩),该步骤分别采用全局平均池化和全局最大池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合。
②:分别将全局最大池化和全局平均池化结果进行MLP(多层感知机)操作,MLP在这里定义与SE的操作一样,为两层全连接层,中间采用ReLU激活,最后将两者相加后利用Sigmoid函数激活。
③:将reshape过后的权重值与原有的特征图做乘法运算(该步骤采用了Python的广播机制),得到不同权重下的特征图。
空间结构主要分为以下三个方面:
①:将上述通道注意力操作的结果,分别在通道维度上进行最大池化和平均池化,即将经过通道注意力机制的特征图从(N,C,H,W)转换为(N,1,H,W),达到融合不同通道的信息的效果,然后在通道维度上将最大池化与平均池化结果叠加起来,即采用torch.cat()。
②:将叠加后2个通道的结果做卷积运算,输出通道为1,卷积核大小为7,最后将输出结果采用Sigmoid函数激活。
③:将权重值与原有的特征图做乘法运算(该步骤采用了Python的广播机制),得到不同权重下的特征图。
代码如下:
1 | |
另一利用注意力模块的ODConv:即插即用的动态卷积
一定程度上讲,ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。ImageNet分类与COCO检测任务上的实验验证了所提ODConv的优异性:即可提升大模型的性能,又可提升轻量型模型的性能
动态卷积这几年研究的非常多了,比较知名的有谷歌的CondConv,旷视科技的WeightNet、MSRA的DynamicConv、华为的DyNet、商汤的CARAFE等
常规卷积只有一个静态卷积核且与输入样本无关。对于动态卷积来说,它对多个卷积核进行线性加权,而加权值则与输入有关,这就使得动态卷积具有输入依赖性。它可以描述如下: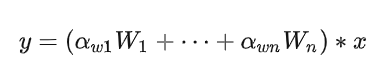

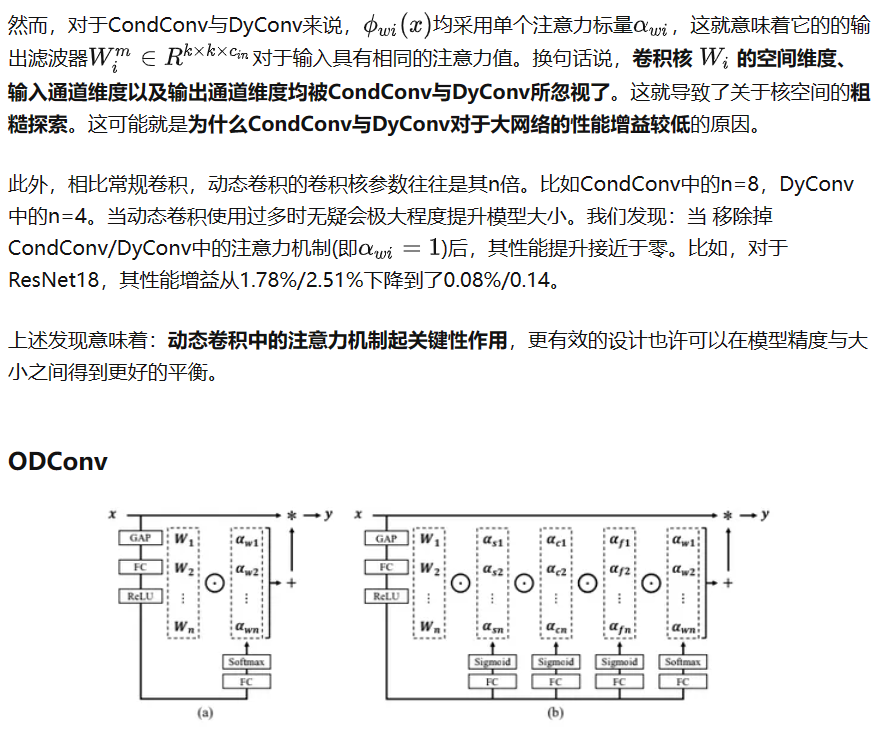
ODConv比一般的动态卷积效果都要好,比一般的注意力机制效果也要好,其实动态卷积与注意力机制是从模块中不同角度进行解析,动态卷积是相比较于常规卷积,最终需要与输入相乘,与输入有关,而常规卷积与输入无关;注意力机制是相对于特征图的四个维度比较的,也即卷积方式不一样,以往是直接进行特征图与卷积核进行卷积来获取特征,而注意力机制就是将特征图分别对四个通道进行压缩,来获取对比某一通道在特征图的影响力,再分别与卷积核进行线性加权,最后与输入相乘。因此像动态卷积与注意力其实一个东西,只是ODConv是考虑到所有维度的注意力,因此效果最好
参考链接:https://zhuanlan.zhihu.com/p/468466504
5.在yolov5中添加ODConv
1.首先在common.py文件中添加代码
1 | |
2.在yolo.py文件中添加对应的CBAM
1 | |
在yolov5.yaml文件中则需要除了backbone网络中第一个卷积之外,其它卷积都可以替换为ODConv
例如替换head中一个卷积conv
1 | |